HackNY Spring 2015 Hackathon One-Two
| Categories: hackathon, projects#TL;DR
I won second place at the HackNY Spring 2015 Hackathon with 🐤🎶 (chirp). And I also won first place with GLaPEP8(!) Apparently I’m the first person to win two podium places at a HackNY hackathon.
Congrats to GLaPEP8 for winning 1st place at #hackny - Adam won first and second! pic.twitter.com/WASGOlqmir
— Major League Hacking (@MLHacks) March 8, 2015The hackathon was a blast, I really love working full-out in an environment filled with people doing the same. It didn’t hurt to be surrounded by HackNYers, sponsors, and snacks.
#🐤🎶 (chirp)
ChallengePost link, GitHub repo.
The first project I came up with is called ‘ 🐤🎶’. However, I couldn’t submit that name on ChallengePost, so I gave it the alternate title ‘(chirp)’. That wasn’t the end of the issues caused by the name, however: I thought using it as a subdomain broke ngrok in the middle of the demos (but actually, it was just maintenance. Still, a tense 20 minutes for many a demoer).
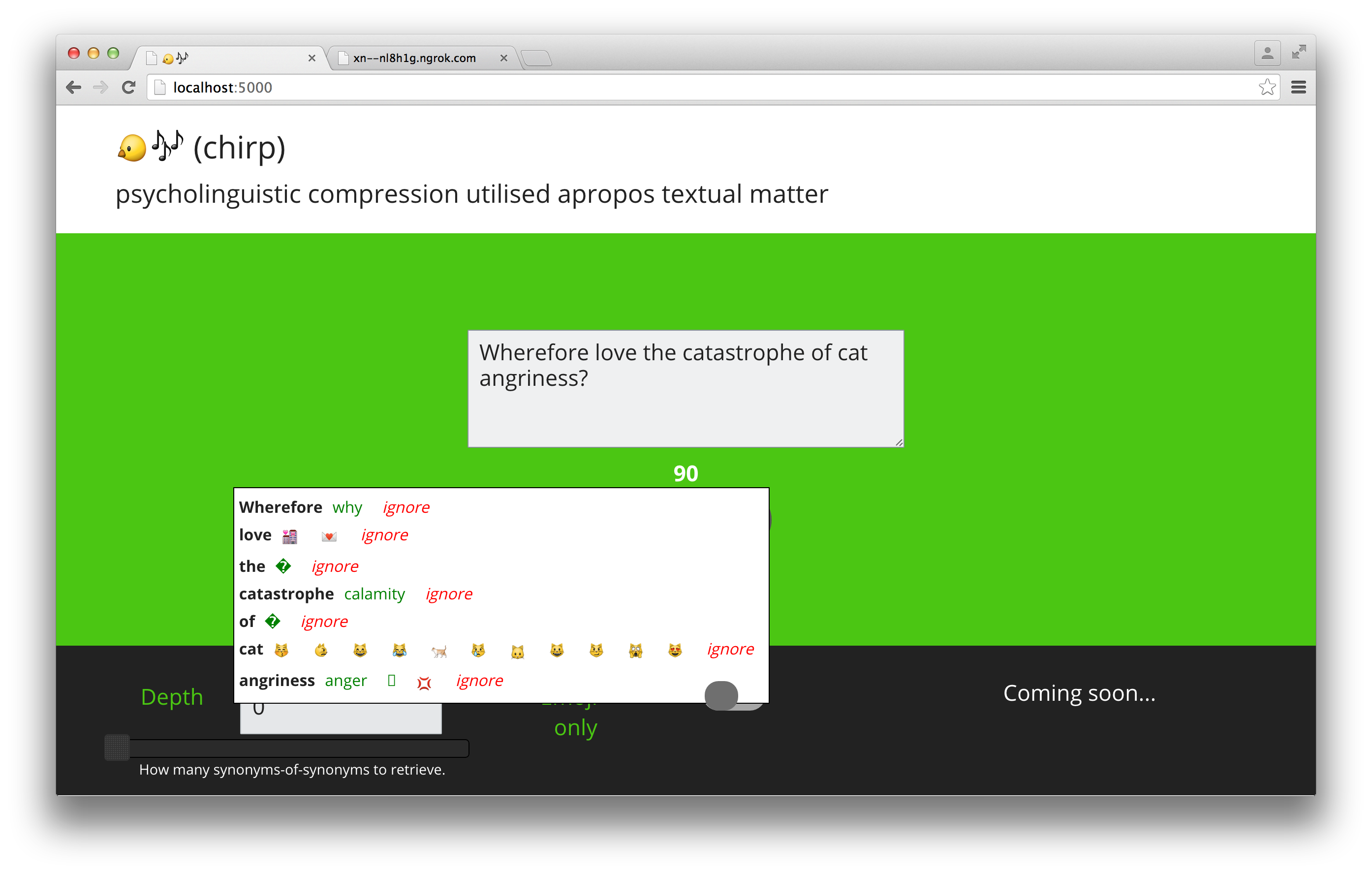
🐤🎶 is a tool to reduce the length of potential tweets. It uses WordNet inside Python’s NLTK to find synonyms for each word in the provided text. For extra concision, it also suggests emoji which might replace some words, and offers to replace stopwords with the NUL character. You might think of this as similar to the lossy pscyhoacoustic compression used in MP3s, in that it retains the human-interpreted meaning while reducing the amount of data the machine needs to store. In reality, semantic compression is a thing in NLP, but the approach used here is as-simple-as-possible, and aims not to reduce the total number of words needed to represent a corpus, but the total number of characters to represent a single text.1 I’ve got a few ideas up my sleeve about how to improve it, though.
The process of developing this was surprisingly smooth. I’ve used NLTK quite a bit in the past, the most difficult part was understanding WordNet’s jargon (e.g. what exactly lemmas are). I wanted to add a bunch of configuration options, for example to only replace with more-specific or less-specific terms (hyponyms or hypernyms). That didn’t make it into v0.1, but there are two options on the page: one to only suggest emojis, and depth which controls how many levels of synonym-of-synonym to suggest. The backend uses flask, a library I’ve built so many projects with I can pretty much use it blindfolded.
The frontend was more complicated. It uses the usual suspect, but instead of Twitter Boostrap or foundation, I went for the minimalist tuktuk, which worked really well and looks delightful.
It took me quite a while to settle on how to display the suggested changes. I thought about just having a basic form which returns the edited text, maybe displayed side-by-side with the original. In the end, I decided that inline suggestions would be cooler, so I searched for a Javascript spelling correction library that would display the suggestions and UI while letting me handle the backend. This wasn’t so easy. Many plugins require you to have a static dictionary, which was no good for me, both for quick-iteration reasons and because there would need to be one dictionary for each combination of configuration options. All the other plugins I found used pre-existing spellcheck backends — this isn’t so surprising, because who wants to build their own spellchecking engine (except perhaps Peter Norvig). Worse than that, almost all of them supported the not-quite-public now-deprecated Google Spellchecker API.
That said, I did end up using jquery-spellcheck by brandonaaron, which does call the Google API. It was straightforward to make it use my backend, because the library uses a proxy script, which I just replaced with my own. Working out what to serve from the backend was less easy, however. As it turns out, defunct-and-never-quite-official APIs don’t have great documentation. I used the example return value in the documentation from this Java library to reverse-engineer the XML return format. For future reference, it looks2 like this:
<?xml version="1.0" encoding="UTF-8"?>
<spellresult error="0" clipped="0" charschecked="0">
<!-- one 'c' tag for each word which needs to be changed -->
<c o="0" l="6" s="1">hello Helli hell hallo hullo</c>
<!-- attributes:
o: offset from beginning of string at which the replacement should happen
l: number of characters to replace (i.e. length of original word)
s: not sure
-->
<!--
The contents of the 'c' tag is a space-delimited list of suggested
replacement words.
-->
</spellresult>‘charschecked’ doesn’t actually need to be set, and you can use any number of spaces between the suggested replacement words. If I end up working on 🐤🎶 more, I’m going to have to modify this format, because I’d like to be able to suggest replacments for phrases, not just single words.
I made minor modifications to jquery-spellcheck so that it sends additional URL-parameters on its AJAX call for the depth of synonyms and emoji-only mode.
On another note, I demoed this in Chrome Canary, because the stable version doesn’t have emoji support yet… As a side effect of this project, I found to my surprise both in how many places you can use emoji (like some TLDs, although finding a registrar is another question), but also in how many places they don’t work. I’m going to continue working on the synonym engine part of this because the frontend is pretty much done (and because for my own use I’d prefer a CLI). One interesting option is that — given that WordNet doesn’t just give you synonyms but tells you how words are related — I could replace words with more general (or perhaps more common) ones. This would be more similar to what semantic compression does. It would be cool to see whether replacing words with hypernyms results in something similar to the Getting to Philosophy effect on Wikipedia, where successively clicking the first link on an article will eventually lead you up the hierarchy of more-and-more general topics towards philosophy.3 Stay tuned via GitHub.
Also, thanks to JZ Forde for providing initial feedback and encouragement.
Next up: the winner, GLaPEP8.
-
Actually, because we’re targeting Twitter, the aim is to minimise the number of codepoints in NFC-normalised format (hence why emoji are useful to this goal). ↩
-
Of course, this specification might only apply to the API as implemented in jquery-spellchecker… ↩
-
By the way, I called it back in 2010. ↩