How To Write A Neural Network in a Single Tweet
| Categories: code, MLNeural networks! They’re everywhere! Can you use them for everything? Do they have anything to do with brains? Are they Skynet or just fancy regression? Let’s find out!
One of the best ways to demystify something is to build it yourself. On the other hand, one of the best ways to re-mystify it is to obfuscate the code you wrote. So I set myself the challenge of implementing a neural network from scratch which fits exactly in the 280 characters of a single tweet. Here it is:
from numpy import *
— Adam Obeng (@Adam_Obeng) April 8, 2019
r=random
c=hstack
p=dot
N=r.randn
s=lambda x:1/(1+exp(-x))
a=lambda x:s(x)*(1-s(x))
h,j=X.shape
w=N(5,j+1)
e=N(1,6)
for i in r.randint(0,h,1000*h):o=c((1,X[i]));m=p(w,o);n=c((1,s(m)));d=p(e,n);b=0.02*(Y[i]-s(d));g=b;w+=outer(e[:,1:]*a(d)*a(m),o)*b;e+=n*g*a(d)
Or if you prefer, here it is as a gist.
This really is a neural network, albeit a super minimal one: a 1 hidden-layer MLP with sigmoid activations, fit with SGD. If you actually wanted to use it, you would set X to be a numpy array of features and Y a numpy array of labels, and after running the code, the trained weights are in variables w and e. The GIF below shows what that looks like training on some example data generated with sklearn.datasets.make_circles. On the left is a scatter-plot of the training data and predicted values, and the graph on the right shows the training MSE loss as the SGD steps increase.
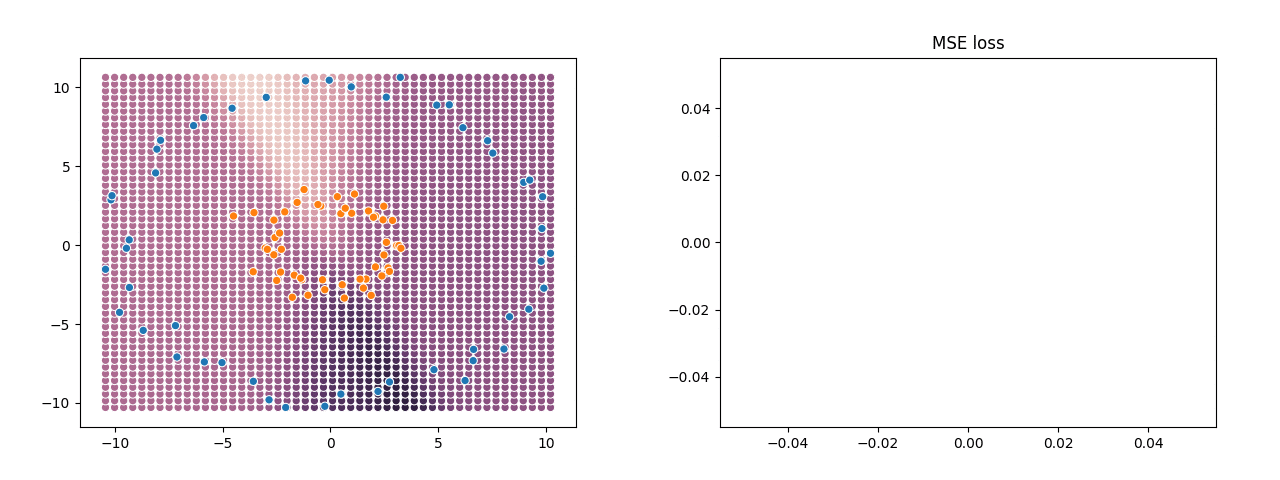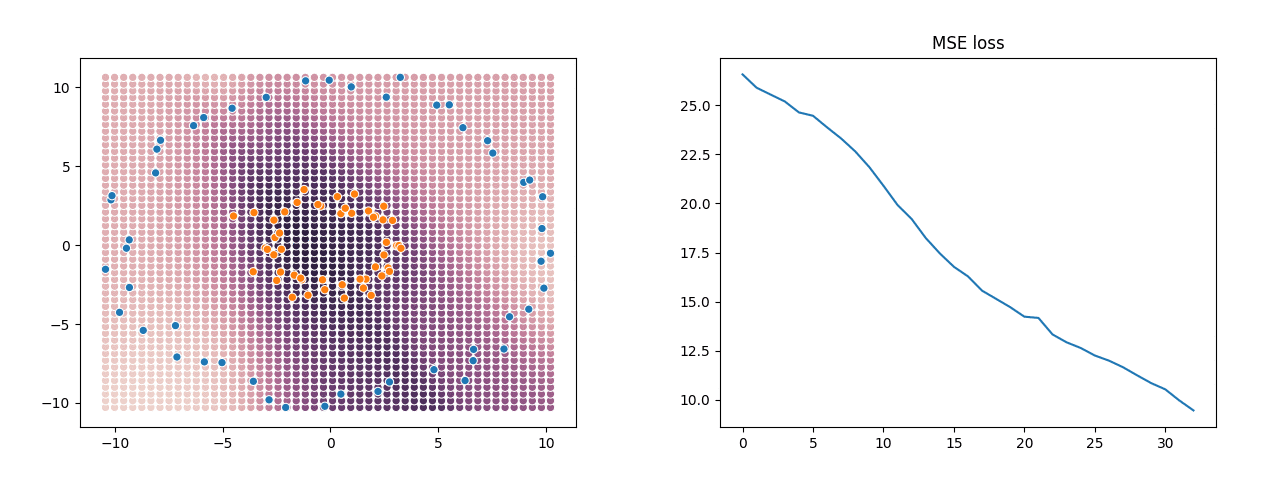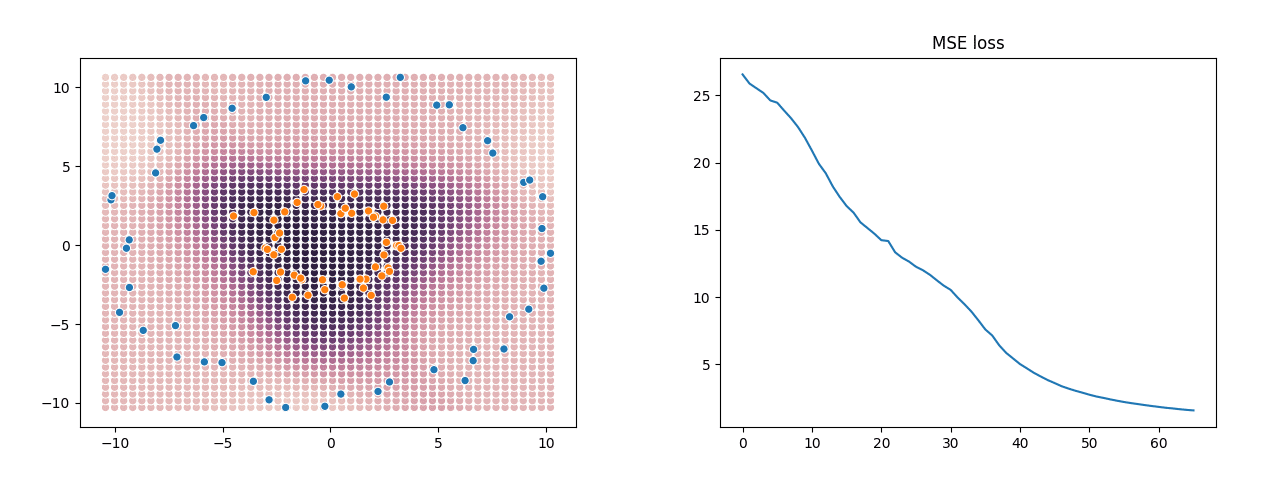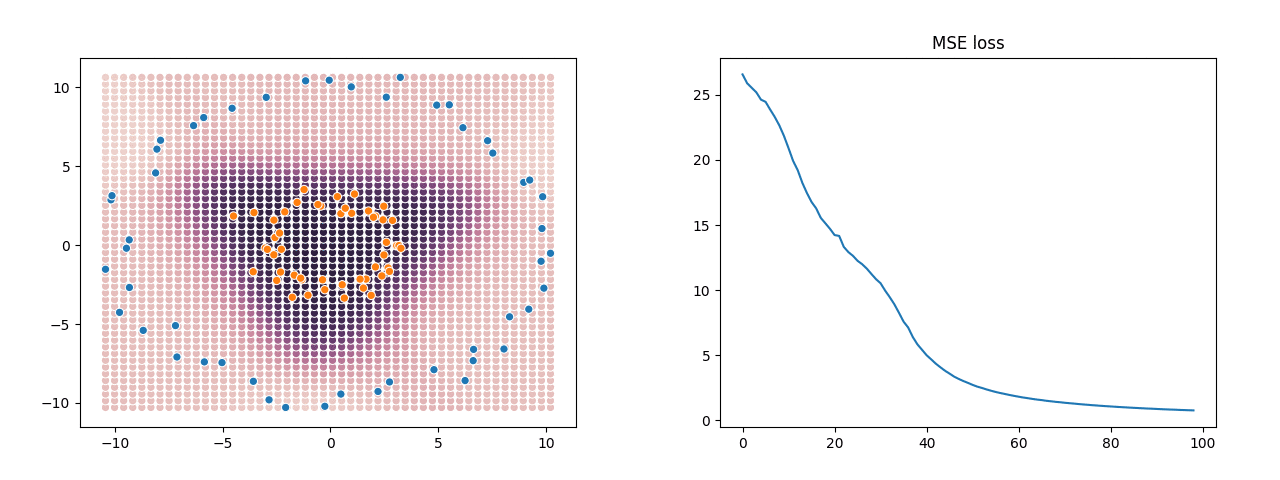
This very simple network does a good job at finding a reasonable boundary between the orange points and the blue points even though they’re in two concentric rings — something which a linear classifier would be utterly incapable of doing.
A minimal neural network
In putting together this code, I had to do two things: figure out how to write a minimal neural network and training loop without using any external libraries, and then code golf it down to 280 characters.
So to explain the implementation first, let’s look at a de-minified version of the code, with more interpretable variable names and comments:
You’ll notice that I’ve allowed myself the use of numpy. I don’t know that you could do this in Python without it, so I think this still counts as “from scratch”. There were a few tricky steps in figuring out how to write this in the simplest way possible. Quite a few of the programming-oriented minimal neural network tutorials end up implementing network classes, which is unnecessary for the purposes of an implementation which doesn’t need to be extensible and also obscures how the thing actually works.
I ended up referring to a few other “neural network for hackers” posts, of which this is the most succinct example. Even so, I’ve written out the code above with descriptive variables names — I think the practice of writing code as if it was algebra is detrimental to understanding.
Code Golfing
The way I’ve written the code above already takes into account some of the higher-level golfing: the derivative of the sigmoid can be defined in terms of the sigmoid, and using intermediate variables for the output from each layer before the activation function means that these expressions can be re-used in the backprop step.
Using single-character variable names is the cheapest golfing strategy, but sometimes it’s not worth re-defining existing variables to make them shorter. outer is only used once, so re-naming that to a shorter name would result in strictly longer code. I was also tempted to use tuple unpacking to define multiple variables on the same line, but that doesn’t really save any characters (unless your right-side variable is already a tuple).
I went back and forth on including newlines in the code. On the one hand “a neural network in one line of Python” sounds pretty snappy, but on the other using semi-colons is a cheap trick and doesn’t reduce the character count. The one place where they are useful is inside the loop where they save on both a newline and a tab character.
There’s one final secret: I wanted to include my name in the code in a way that was integral to the implementation. There were not so many variable names which could be freely changed, so this was a bit of a challenge, and it actually makes the solution use a few more characters than would otherwise be necessary. Figuring out which ones is left as an exercise to the reader.